
Blog
-

Launching the AI Resist List
By Aphie Gover, Bruna Martins, Laura Hernández and Sarah Ruth In October 2025, we published the Resisting, Refusing, Reclaiming, Reimagining: Charting Challenges to Narratives of AI Inevitability paper, and the response was immediate and overwhelming. The positive reaction from many groups, including corporate channels we would never expect to be mentioned in, showed that there…
-

The growing call for public (critical) AI literacy in the UK
Skills-based digital literacy has failed to provide public benefit. So why is upskilling the UK’s only plan? As part of a range of bombastic statements about the UK’s uncritical embracing of AI in everything, the Government recently announced the AI Skills Boost. It promised “free AI training for all,” and claimed that the courses will…
-

The Hidden Harms of Chatbot Use – Mapped
A broad taxonomy of AI chatbot harms caused to individual users Introduction At We and AI we have been concerned by the lack of awareness of the wide range of harms caused by AI chatbots for a long time. Despite the huge encouragement to use chatbots as companions, coworkers, doctors, teachers, counsellors, life advisors, friends,…
-

Review of “Exploring Metaphors of AI: Visualisations, Narratives and Perception”
A curated research session at the Hype Studies Conference, “(Don’t) Believe the Hype?!” 10-12 September 2025, Barcelona By Cinzia Pusceddu Better Images of AI and We and AI have been exploring the role of visual and narrative metaphors in shaping our understanding of AI. As part of this we invited some researchers who have been…
-
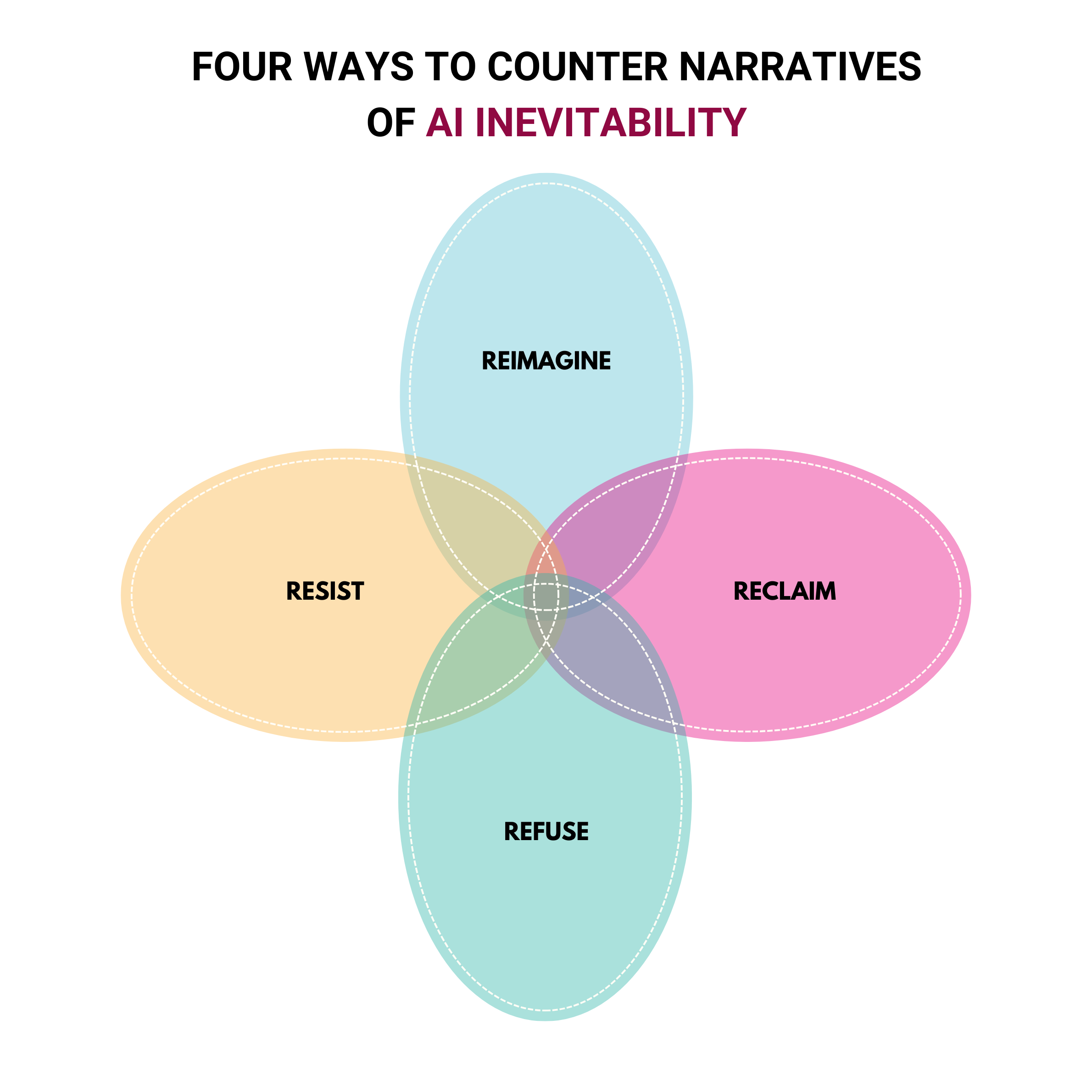
Resisting, refusing, reclaiming, reimagining AI: A new framework to challenge the inevitability of extractive AI
At We and AI we have been working on several projects based around decoding and unpicking the AI hype narratives, framing, words and pictures that are used to legitimise AI which does not work for public good. One narrative we have found to be most insidious is one used to disempower anyone who challenges the…
-

Exploring Community Visions of AI and Public Good through Critical AI Literacy
Sharing the learning from an intervention to gain deeper insights in public deliberation In late 2024, We and AI were commissioned by the Ada Lovelace Institute on their project ‘Making good’, to provide a critical AI literacy programme. Through deliberative engagement with communities in Belfast, Brixton and Southampton, the research explored how people feel about…
-

Three barriers to fostering critical AI literacies
We have been enjoying working with Professor Kathryn Conrad to define some key elements of critical AI literacy, including how it differs from AI and digital literacy, and why it is currently needed as an addition to AI literacy. There is a growing recognition of the need for ways of learning about AI that address…
-

Reflecting on 5 Years of We and AI
Celebrating Community, Curiosity, and Collective Change Rameez Raja is a data analytics engineer, storyteller, currently pursuing an MSc in AI at the University of Bath. He is also an active We and AI volunteer, and shares this perspective on the first five years of non-profit organisation We and AI. Last month, I had the privilege…
-

Deepfakes and Synthetic Media Workshops
With the rise of generative AI tools like ChatGPT and image generators, deepfakes have become more convincing and widespread. Anyone with access to a computer can replace a person’s face on-screen with another’s, or create a convincing impression of a person’s voice using speech synthesis. While these technologies may have creative and educational uses, they…
-

What did we learn from “Framing Deepfakes”?
Dr Patricia Gestoso and Medina Bakayeva This is a recap of ane event we hosted in July 2024. Watch the event recording here. In light of the malicious uses of deepfakes, governments have engaged in policy debate, media outlets have frantically reported on the issue, and academics explored the technological advancements of AI-generated media from different…
-

Free online webinar to explore research on the ethical implications of AI Hype, by We and AI on 23th Sep 2024
*** Explores the overinflation and misrepresentation of AI capabilities, featuring insights from over 30 experts across various disciplines.*** Examines AI hype’s impact on public discourse, policy, business, and more. **** Hosted by We and AI, a nonprofit focused on AI literacy for critical thinking. [London, 2024.09.09]: We and AI, a nonprofit organisation committed to enabling…
-

Leaving AI explainers up to tech companies: What could go wrong?
Opinion: By Tania Duarte In the absence of any funded civil society or national school and adult initiatives in the UK, tech companies fill the vacuum. For instance, Snapchat.AI have an AI literacy guide and Google DeepMind have developed Experience AI. It can seem sensible to educators and policymakers to make use of free resources…